Using deep learning to detect abusive sequences of member activity
7 min read
Production sequence modeling for platform abuse detection at LinkedIn: request-path token streams, timing features, LSTM/CNN scoring, weak-label bootstrapping, and embeddings for coordinated automation.
At LinkedIn, the Anti-Abuse AI team built and ran models for fake accounts, account takeovers, scraping, spam, and other forms of automated platform abuse.
This post revisits a production deep learning model I built with my colleague Beibei Wang. The key idea was to stop treating scraping as a set of hand-built counters and instead model the ordered language of member activity: what an account requests, in what order, and with what timing. The original LinkedIn Engineering write-up and a recorded talk are linked under Resources.
The Modeling Problem
Fake account rings, account takeovers, API abuse, and scraping look different at the product layer, but they share a common dependency on automation. A bad actor controlling a fleet of accounts, sending spam through a browser extension, or harvesting profile data is usually running a repeatable process. That suggests a useful abstraction: learn the behavior of automation itself rather than building a separate feature set for every product surface.
The first production use case was logged-in profile scraping. That was a good stress test because careful scrapers do not simply blast traffic. One scraper we studied viewed profiles in short bursts and deliberately revisited profiles it had already seen. Another viewed roughly seventy distinct profiles in a day with randomized delays. Both stayed within activity ranges that could plausibly be human, making aggregate request counts a weak detector. The discriminative signal was the joint pattern of request types, ordering, repetition, and timing.
That setting has three modeling constraints. The representation has to work across many site surfaces. It has to retain fine-grained behavioral structure that aggregate features discard. And it has to be robust enough for an adversarial domain where attackers adapt to visible defenses. Labels are also imperfect: scraping does not arrive with clean ground truth, and the natural class balance is extremely skewed.
From Requests to Tokens
Profile views are only one slice of what an account does. Around them sit logins, searches, messaging requests, settings changes, page resources, and the long tail of browser requests that make up a session. The full ordered stream is the behavioral object worth modeling.
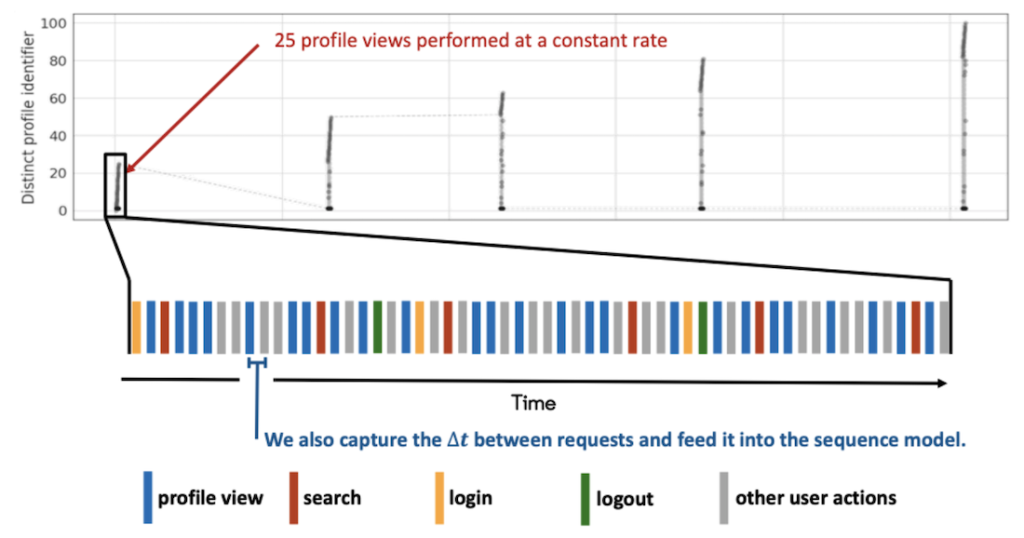
A mock burst of profile views, expanded into the full request sequence around it. The model also consumes the time gap between consecutive requests. (Figure from my LinkedIn Engineering blog post.)
The input pipeline has two important steps. First, raw request paths are canonicalized into standardized path tokens, creating a shared vocabulary across the site. Second, each token is mapped to an integer according to global request-path frequency: common requests get small ranks, rare requests get large ranks. That gives the model a stable categorical vocabulary and a weak global prior about how ordinary each request type is.
Timing is kept as a parallel signal. For each adjacent pair of requests, the model receives the elapsed time between them. In NLP terms, the request-path stream is the sentence, the standardized paths are tokens, and the inter-request delays are a second channel that tells the model how the sentence was paced.
What the Model Sees
A useful way to visualize an encoded sequence is a grid: 200 consecutive requests, twenty per row, colored by how common each request is. Here is a normal, healthy member browsing the site:
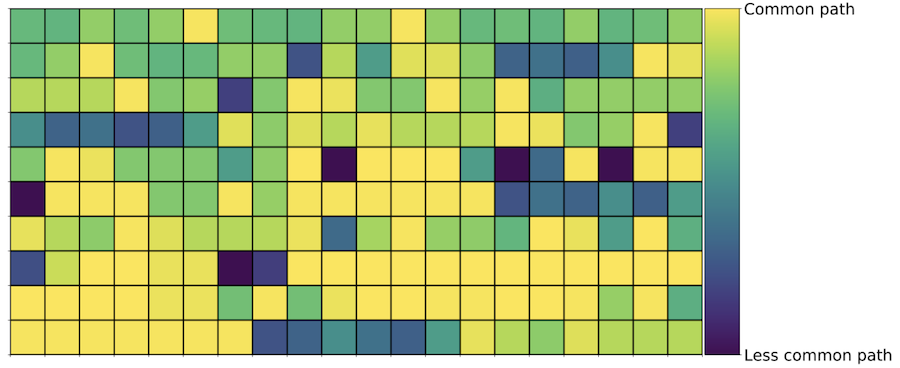
The first two hundred requests from a legitimate member, colored by request-path frequency. Organic browsing produces a varied, heterogeneous texture. (Figure from my LinkedIn Engineering blog post.)
And here is a scraper:
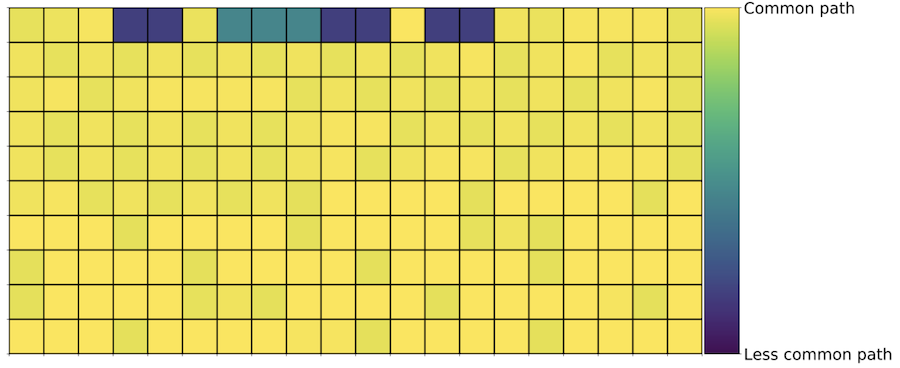
The same visualization for an automated scraper. Scripts hammer a few request types and fail to reproduce the subtle variety of real browsing. (Figure from my LinkedIn Engineering blog post.)
This visualization is not the model; it is a sanity check on the representation. It shows why the raw sequence contains signal that summary features lose. A script can randomize delays and revisit targets, but it still has to reproduce the incidental mix of requests that real browsing creates: navigation, searches, profile views, background resources, pauses, and context switches. The encoded sequence exposes that texture directly.
Architecture: Local Motifs, Timing, Memory
The model is a supervised sequence classifier with two input branches. The request-path branch starts with learned embeddings over the frequency-ranked path tokens. Those embeddings let the model learn a dense representation of request types from the abuse-detection objective rather than from manually assigned semantics. One-dimensional convolutions then detect local motifs: short subsequences that may be suspicious wherever they appear in the stream.
The timing branch processes the inter-request time gaps. After the path and timing representations are concatenated, an LSTM models longer-range dependencies across the account’s activity window. A final dense layer produces an abuse score.
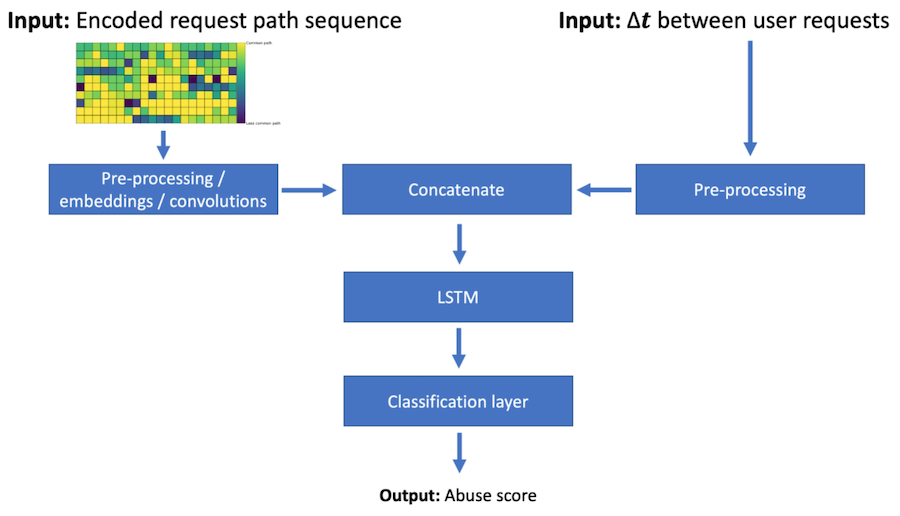
The two-branch architecture: encoded request paths plus inter-request time gaps, concatenated into an LSTM with a final classification layer that outputs an abuse score. (Figure from my LinkedIn Engineering blog post.)
The architecture has a useful inductive bias. Convolutions capture local behavioral phrases, timing features capture cadence, and the LSTM captures longer sequential context. The model is still supervised, but the feature engineering burden moves from product-specific counters to a general event representation that can be reused across abuse types.
Labels From an Unsupervised Teacher
Supervised sequence models need labels, and scraping does not come with clean ground truth. The labels for this model came from a different production signal: the isolation forest outlier-detection approach we used for automation detection. Those labels could be augmented with examples from known historical attacks.
This is a weak-supervision pattern. An unsupervised or rules-assisted system produces high-confidence labels; a supervised sequence model then learns from the much richer request stream. The student model is not limited to reproducing the teacher’s feature space, because its input is the raw standardized activity sequence.
Evaluation at Natural Class Balance
The initial proof-of-concept model was evaluated out of time, on data from well after the training period, at the natural class balance. That matters: a balanced offline sample can make a rare-abuse problem look cleaner than it is. In the real distribution, scrapers are a small fraction of total activity, so the useful question is whether the high-score tail is dominated by the abusive population.
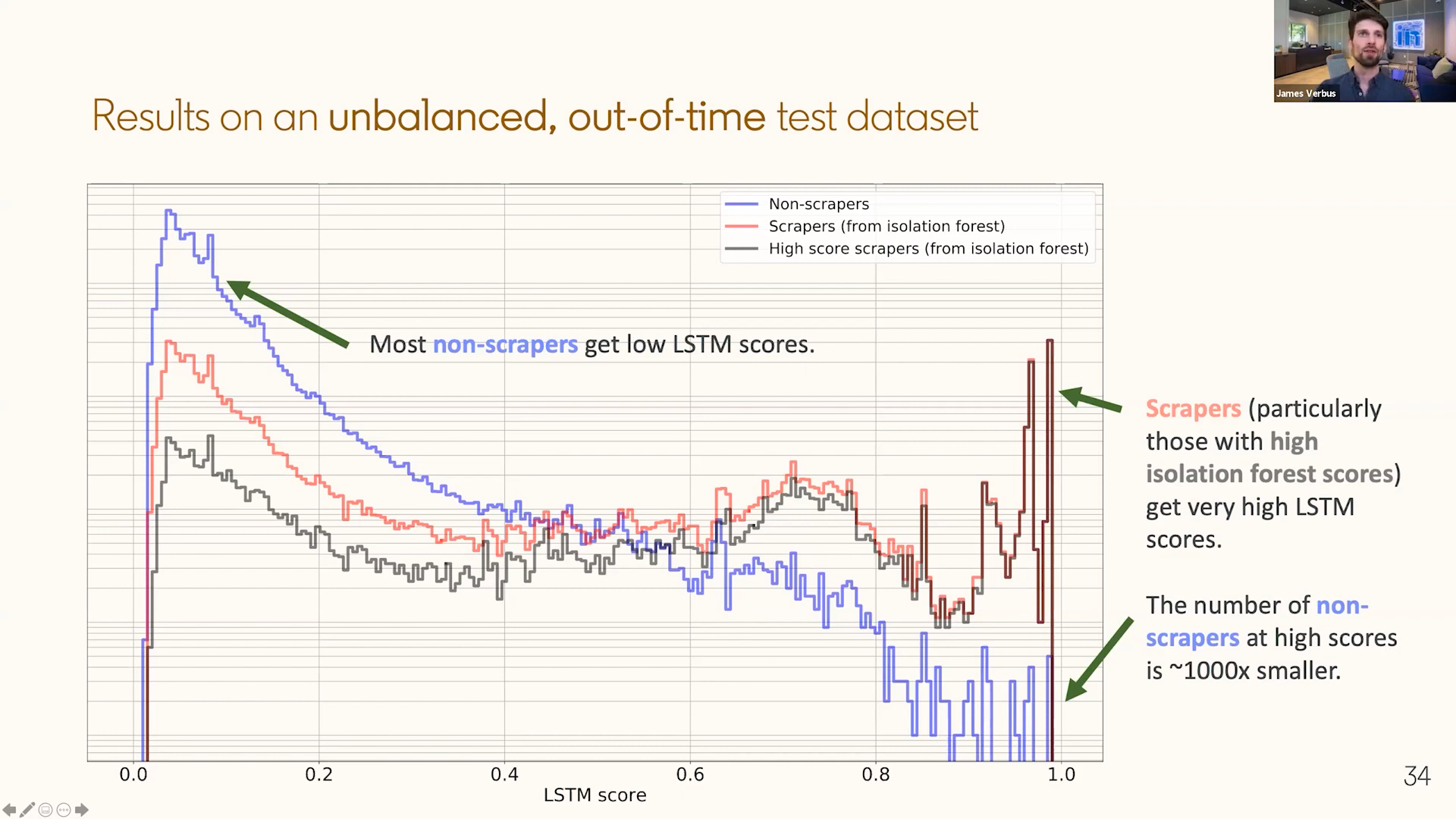
Out-of-time score distributions at natural class balance. Non-scrapers concentrate at low LSTM scores, while high-confidence scrapers dominate the high-score tail. (Slide from my Scale AI talk.)
The score distributions separated strongly. Non-scrapers concentrated at low scores, while labeled scrapers concentrated at high scores, with roughly a thousandfold separation between the distributions at the high-score end. That is the operational property the model needed: a ranking that surfaces sophisticated low-volume scrapers without flooding the defense workflow with normal members.
Embeddings and Coordinated Automation
The same representation also produces activity sequence embeddings. Accounts running the same browser extension, scraper, or automation framework tend to traverse the site in similar ways, so their learned representations can cluster together. That gives defenders another handle on coordinated activity: instead of only asking whether one account looks abusive, ask which accounts are behaviorally close to each other.
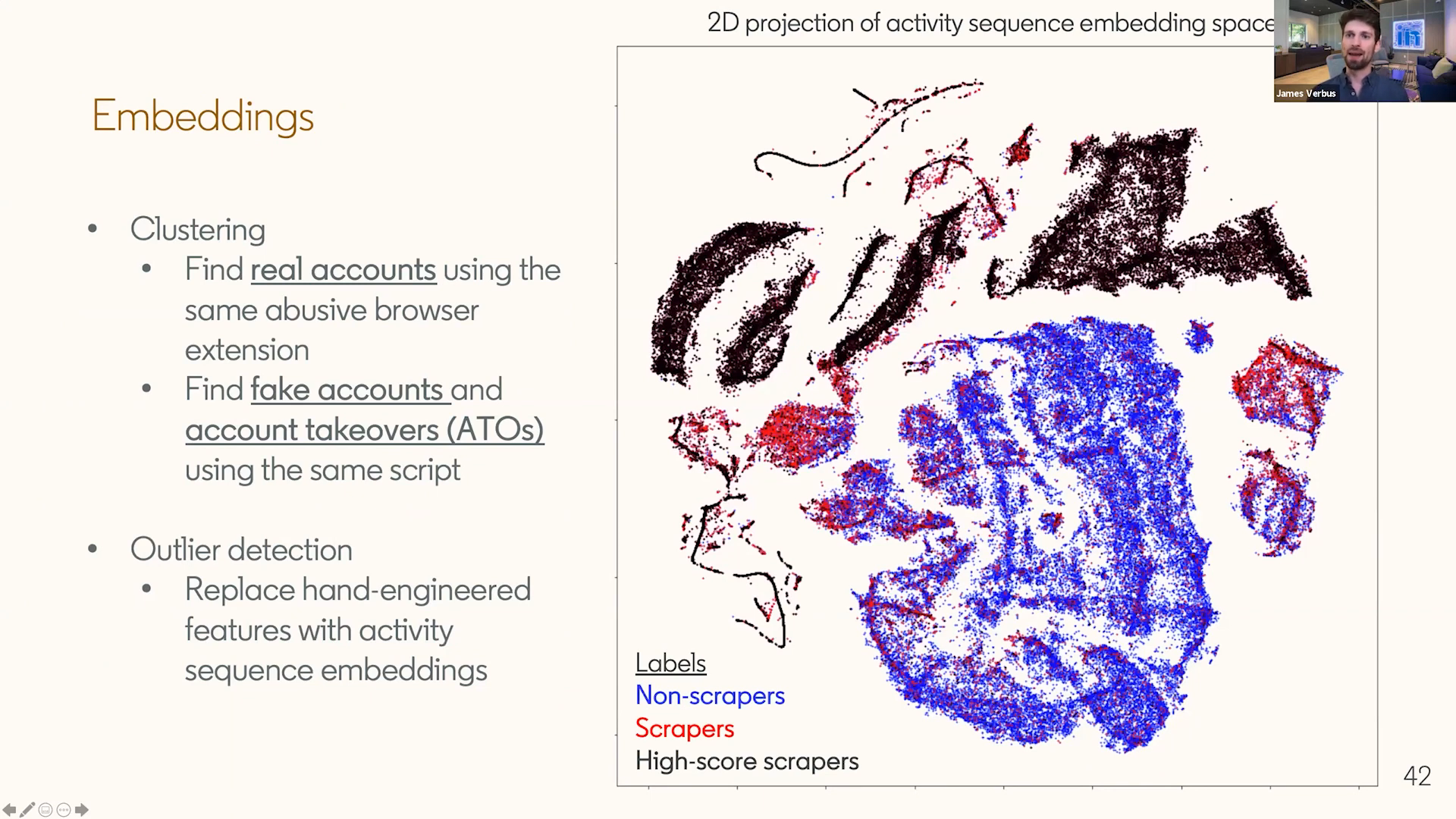
A two-dimensional projection of activity sequence embeddings. Accounts associated with similar scripts or extensions land in nearby regions of the learned space. (Slide from my Scale AI talk.)
The embeddings can also serve as features for downstream outlier-detection models, replacing hand-engineered activity summaries with learned representations of the sequence.
Resources
Blogs
Videos
Patents
- US Patent 11,936,682: DEEP LEARNING TO DETECT ABUSIVE SEQUENCES OF USER ACTIVITY IN ONLINE NETWORK
- US Patent 11,991,197: DEEP LEARNING USING ACTIVITY GRAPH TO DETECT ABUSIVE USER ACTIVITY IN ONLINE NETWORKS
- US Patent 12,500,923: IDENTIFYING COORDINATED MALICIOUS ACTIVITIES USING SEQUENCES OF REQUESTS