Finding AI-Generated Faces in the Wild
4 min read
Detecting GAN- and diffusion-generated faces in the wild: one classifier across ten synthesis engines, robust to low resolution and heavy compression.
Our 2023 detector exploited the rigid facial geometry of StyleGAN images, and it worked extremely well against that family of generators. But the generative landscape did not hold still. Within a year, a fake profile photo could just as easily come from Stable Diffusion, DALL-E 2, or Midjourney, none of which share StyleGAN’s telltale alignment, and it would arrive small and recompressed by whatever upload pipeline it passed through.
Finding AI-Generated Faces in the Wild, again with Professor Hany Farid at UC Berkeley, takes on that messier problem: one classifier that detects AI-generated faces across both GAN and diffusion engines, and keeps working at the reduced resolutions and compression levels real platforms actually see. We published it at the Workshop on Media Forensics at CVPR 2024.
One Classifier, Ten Engines
We trained and evaluated against 18 datasets: 120,000 real profile photos from LinkedIn members, plus another 105,900 synthetic images spanning ten generation engines. The GAN side includes generated.photos, StyleGAN 1 through 3, and EG3D; the diffusion side includes DALL-E 2, Midjourney, and Stable Diffusion 1, 2, and xl. Six engines were used for training; four were held out entirely to test generalization.

Representative AI-generated images from the ten synthesis engines used for training and evaluation. Some engines contribute faces only; others contribute both faces and non-face images. (Figure from the paper.)
At a fixed 0.5% false positive rate, the classifier catches 98% of AI-generated faces from engines seen in training. On the four held-out engines the average is 84.5%, with an honest spread behind it: EG3D transfers almost perfectly (99.5%) and generated.photos nearly as well (95.4%), while Midjourney mostly slips through (19.4%). Generalization is good in some directions and weak in others, and the practical answer is the operational one: fold new engines into training as they appear.
Built for the Wild
The “in the wild” part is the point of the paper. Profile photos do not arrive as pristine megapixel originals; they get downscaled and JPEG-compressed, sometimes repeatedly. Detectors that depend on fragile pixel-level traces tend to die somewhere in that pipeline.
The architecture is straightforward: images are resized to 512 pixels and fed through an EfficientNet-B1 backbone, with the backbone frozen and 6.8 million parameters of scoring layers trained on top. For compression robustness, the training data mixes uncompressed images with JPEG-compressed ones across a range of quality levels.
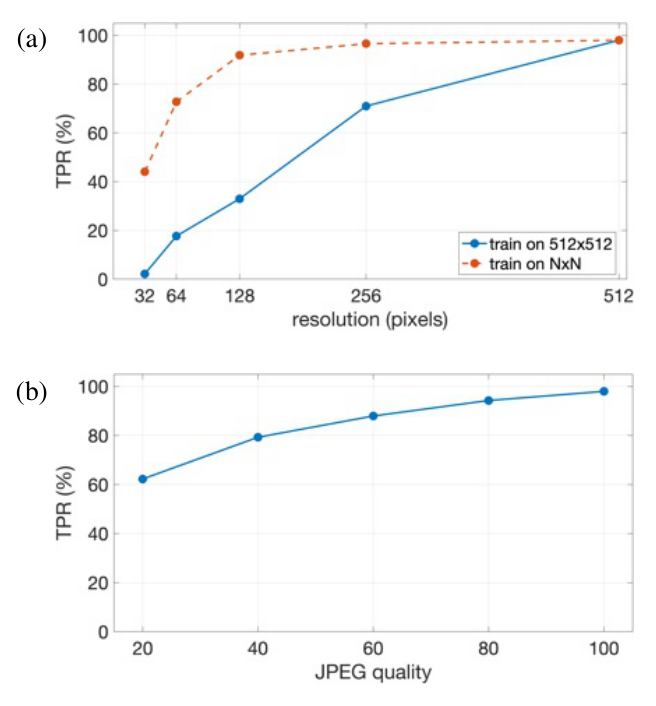
True positive rate as a function of resolution (top) and JPEG quality (bottom) at a fixed 0.5% false positive rate. In the top panel, the solid curve is the 512-trained model evaluated at lower resolutions; the dashed curve is a model trained at the matching resolution. (Figure from the paper.)
The resolution curves carry a deployment lesson. A model trained only at 512 pixels loses most of its detection power on 128-pixel images, but a model trained at that smaller scale stays around 90%. Matching training resolution to the sizes a platform actually serves is what preserves detection on small images. Compression is more forgiving, with detection degrading gradually as JPEG quality falls from 100 to 20.
A Face-Specific Signal, Not a Synthesis Fingerprint
The most interesting result is what the classifier ignores. Non-face images produced by the same synthesis engines are never flagged: the true positive rate on synthetic non-faces is 0%. Part of the explanation is mundane, since the real training photos include some non-faces while every synthetic training image contains a face. But the result also points away from the model relying on a low-level generator fingerprint, some statistical residue of the synthesis process, because that residue would be present in the non-faces too.

Integrated-gradient attributions for AI-generated faces concentrate around the face and other areas of skin. The top row averages 100 StyleGAN 2 faces together; the others are individual examples. (Figure from the paper.)
Integrated-gradient attributions point the same way: the pixels that matter most to the model concentrate around the face and other areas of skin. Together these results suggest the classifier keys on a property of AI-generated faces themselves, which is exactly the kind of signal you want in the wild, because face-level properties survive the resizing and recompression that scrub away forensic fingerprints.