Open Source: Spark/Scala Isolation Forest Library
6 min read
Announcement and resources for LinkedIn's open-source Scala/Spark isolation-forest library for large-scale unsupervised anomaly detection.
I’m happy to announce that my Scala/Spark implementation of isolation forests, an algorithm for unsupervised outlier detection, was open sourced today. It is the implementation the LinkedIn Anti-Abuse AI team relies on in production to find abusive activity, and this post covers why the algorithm fits the anti-abuse problem, how it works, and what the library gives you.
Why Unsupervised Learning Fits Anti-Abuse
Three properties of the abuse domain make unsupervised methods attractive.
First, labels are scarce. New abuse vectors arrive with few or no ground truth labels, which makes training a supervised model impractical and even evaluation difficult. Second, signal per account is thin. An individual abusive account may do very little until the moment it acts, and low-volume abuse hides inside ordinary browsing; confidence often requires noticing many accounts behaving the same way. Third, the domain is adversarial. Attackers adapt to whatever defenses ship, so labels collected today may describe yesterday’s attack. Outlier detection sidesteps much of this: if attacker behavior lands anywhere unusual in feature space relative to organic users, it can be caught without labels.
How Isolation Forests Work
The algorithm, introduced by Liu, Ting, and Zhou in 2008, builds an ensemble of randomly grown binary trees. Each tree takes a sample of training data and, at every node, picks a random feature and a random split value between that feature’s minimum and maximum, recursing until points sit alone in leaf nodes (a height limit keeps trees shallow in practice).
The trick is what isolation costs. Outliers, being few and unusual, get separated quickly and end up with short paths from root to leaf. Inliers, packed into dense regions, take many more splits. In a toy two-dimensional example from one of my talks, isolating a point inside the main cluster took 11 random splits; isolating an outlying point took 5. An instance’s outlier score is derived from its average path length across the ensemble, and averaging over many random trees keeps the variance of that estimate down.
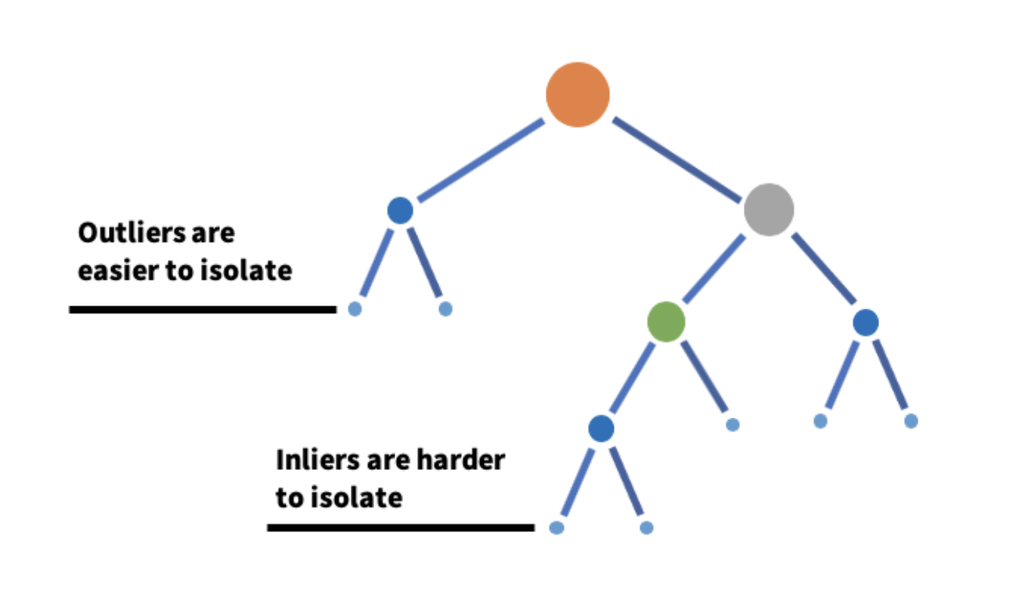
An example isolation tree. Outliers reach leaf nodes in a few splits; inliers take longer paths to isolate. (Figure from my LinkedIn Engineering blog post.)
The technique has practical advantages beyond accuracy. Benchmark studies rate it among the strongest outlier detection methods, and it holds up as feature counts grow. Its computational and memory costs are low enough to train and score large volumes of data nearly interactively. It makes fewer assumptions than the alternatives: nothing parametric about the data distribution, and no distance metric of the kind nearest-neighbor methods require. And it is increasingly widely used, with active academic research extending the algorithm and growing industry adoption, especially in trust and anti-abuse.
The Library
The implementation is Scala on Spark, with distributed training and scoring. It inherits from the Estimator and Model base classes in Spark ML, so it drops into existing Spark ML pipelines, and trained models persist to and load from HDFS. Artifacts are published to Maven Central, so using it is a dependency declaration away.
Training and scoring look like standard Spark ML:
import com.linkedin.relevance.isolationforest._
val isolationForest = new IsolationForest()
.setNumEstimators(100)
.setMaxSamples(256)
.setFeaturesCol("features")
.setScoreCol("outlierScore")
.setPredictionCol("predictedLabel")
.setContamination(0.1)
.setContaminationError(0.001)
val isolationForestModel = isolationForest.fit(data)
val dataWithScores = isolationForestModel.transform(data)
Catching Automation in the Wild
The application I pioneered this for at LinkedIn is automation detection. Score every active member on a day and plot the isolation forest score against activity volume, and the picture is immediately useful: the organic population forms a dense blue bulk, and the sparse high-score region is where automation lives.
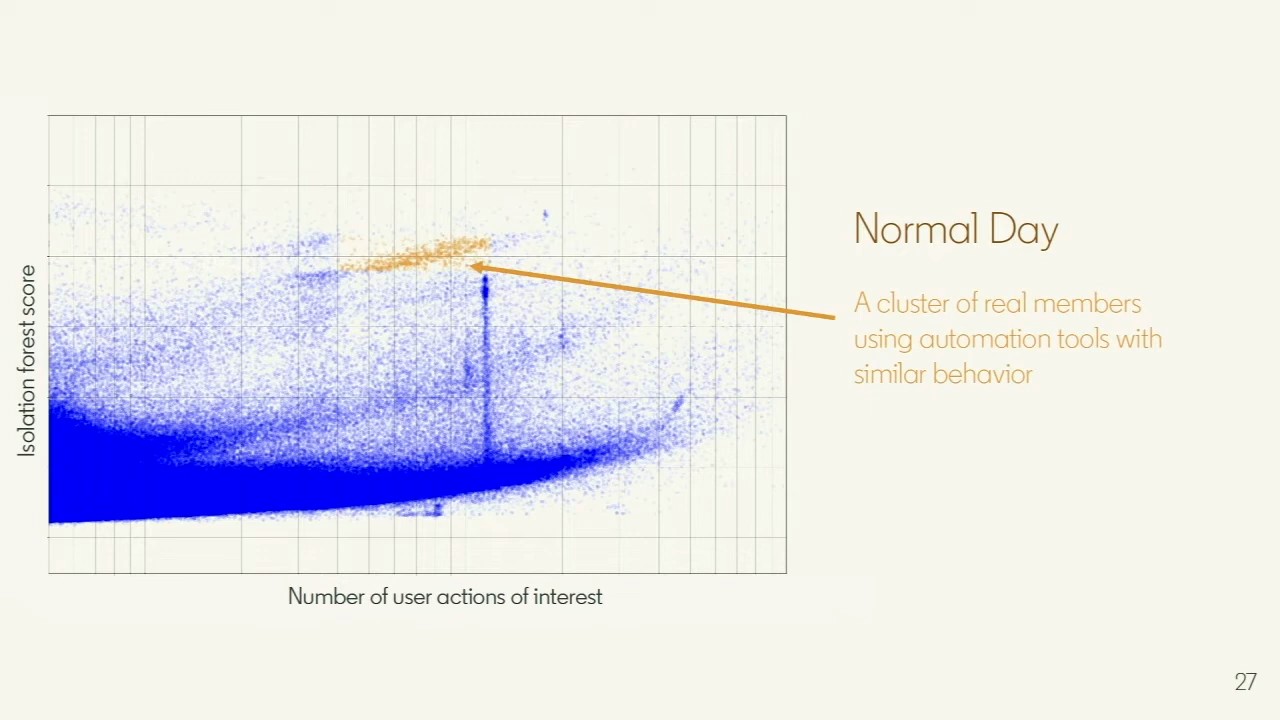
A normal day: every active member, plotted by isolation forest score against activity volume. The highlighted cluster is real members using automation tools with similar behavior. (Slide from my Spark + AI Summit 2020 talk.)
That highlighted cluster turned out, on inspection, to be real members using automation tools, all behaving similarly. Their activity traces made the call easy to trust: one account fired bursts of about thirty actions at a constant rate, paused, then repeated; another ran smaller, more frequent bursts adding up to similar volume. Nothing about that rhythm looks like a person browsing.
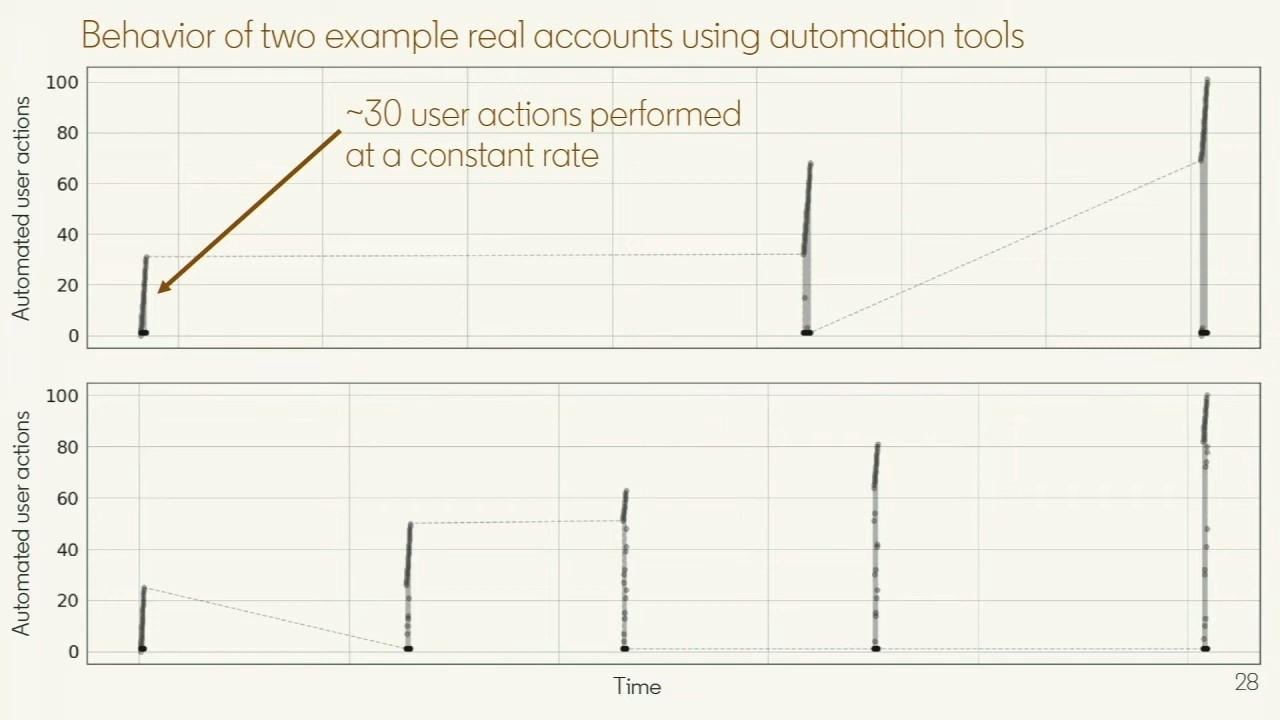
Two accounts from the highlighted cluster: repeated bursts of roughly thirty actions at a constant rate. (Slide from my Spark + AI Summit 2020 talk.)
The more striking case was an attack day. A tight cluster of fake accounts appeared with very high and nearly identical scores, the signature of one actor driving every account with the same script, even though activity volumes varied by an order of magnitude across the cluster.
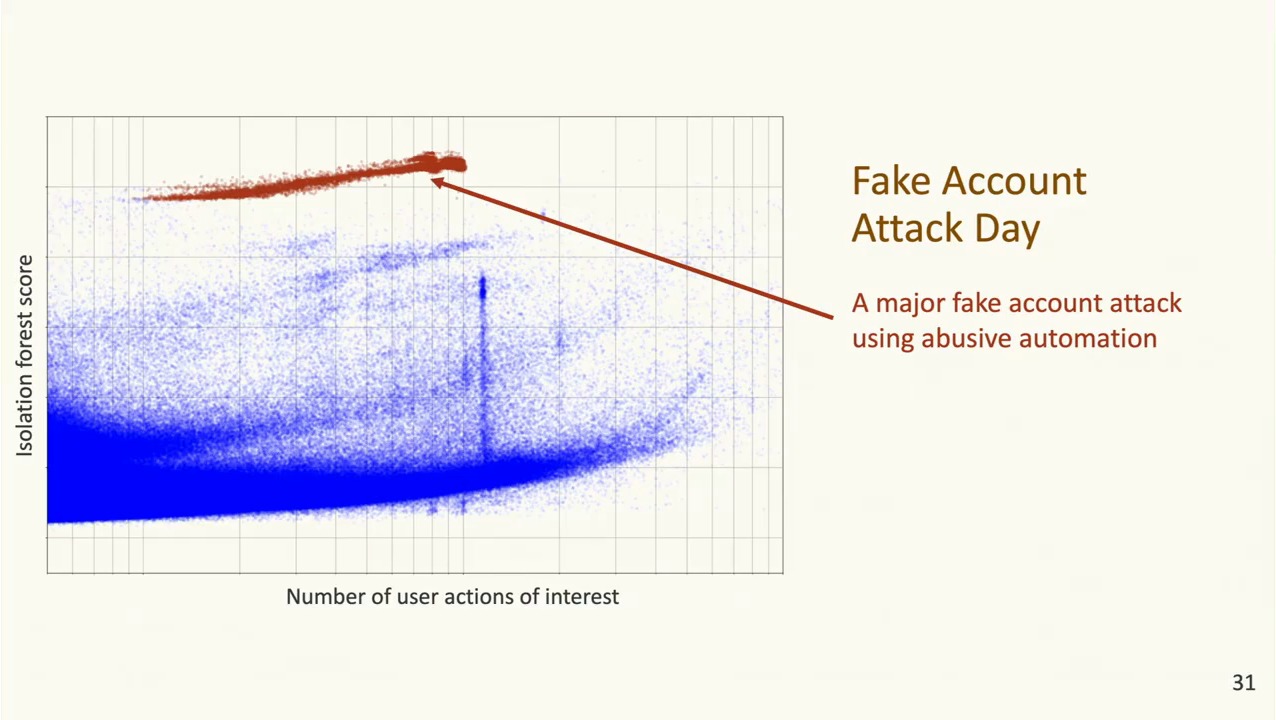
Attack day: a coordinated fake account attack appears as a tight cluster, highlighted in red, at very high score, even though its activity volumes overlap the normal population below. (Slide from my Fighting Abuse @Scale 2019 talk.)
On the volume axis those accounts overlapped substantially with the normal population, and individual accounts kept their activity modest, only tens of actions over the whole day, with randomized delays between requests to blend in. Defenses keyed on volume would have had little to work with. The score axis separated them cleanly anyway, because automated behavior sits far from organic behavior in feature space, and that is exactly what the model isolates.
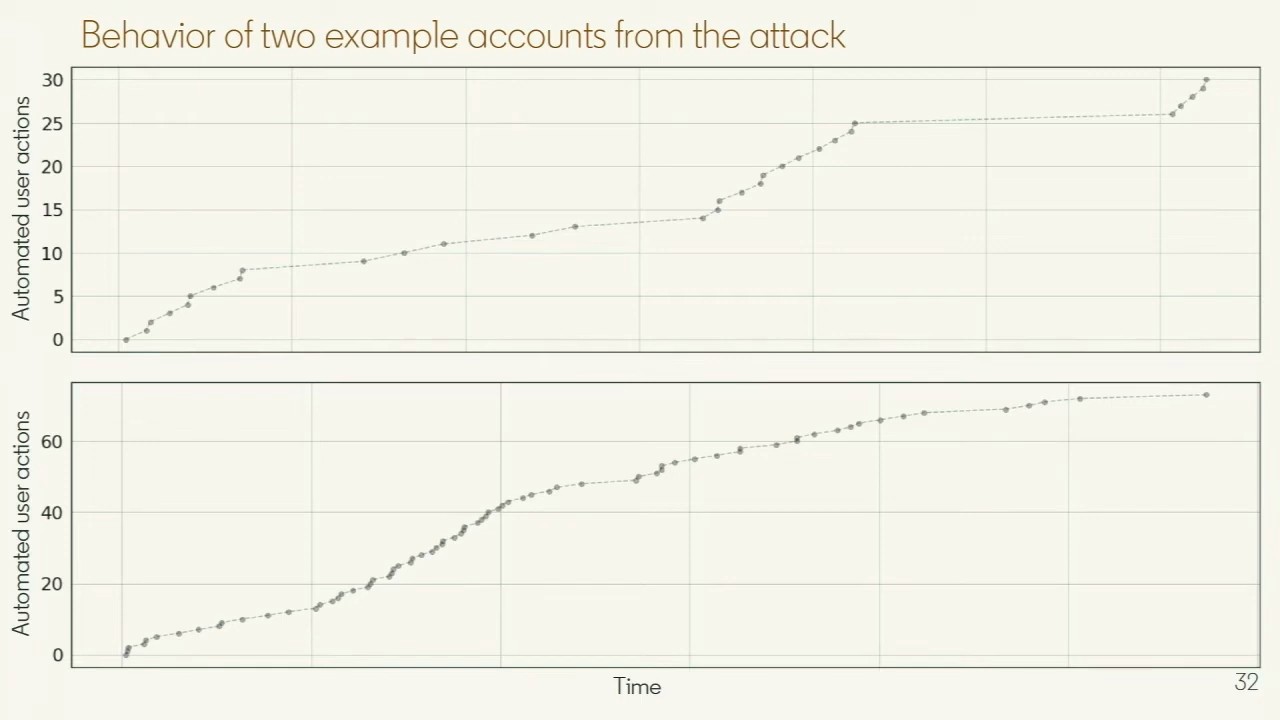
Two accounts from the attack cluster: low daily volumes with randomized timing between requests, and still cleanly separated by score. (Slide from my Spark + AI Summit 2020 talk.)
Beyond Automation Detection
The same machinery transfers to any problem where unusual is suspicious: surfacing sophisticated fake accounts and advanced persistent threats for human review when no labels exist, insider threat and network intrusion detection, account takeover detection from unusual login and post-login activity, alerting on time series such as payment fraud, flagging anomalous feature distributions as an ML health assurance layer, and even spotting underperforming machines in a data center from their resource usage.
Since Then
Update (2026): the library has kept growing. It gained ONNX export in 2024, so standard models trained in Spark can score anywhere an ONNX runtime runs, and Extended Isolation Forest support in 2026, which replaces axis-aligned splits with random hyperplanes (EIF models are not yet ONNX-convertible). The repository now also ships benchmarks against the results reported in the original Liu et al. paper and a reference Python implementation, with scripts to reproduce them.